Serverless Security 101: How to think about serverless cloud security?
Switching to - or even better, starting with - serverless infrastructure is great, especially when you’re a small/medium company. Your expenses only grow when usage grows, you can scale up and down easily, most services are managed, and you can hit the ground running.
Bottom line, instead of worrying about infrastructure, you can focus mainly on your code and providing value for your customers from day one.
However, even though your cloud provider is supplying all the infrastructure you need, you are still responsible for your application security - and yes, using https is a good step, but there’s a lot more to serverless security than using https.
In this post, we’ll discuss the main topics you should take into consideration when designing your serverless applications, and we’ll drill down on each of these topics and how to implement them in future posts in this series.
What you need to protect when using serverless
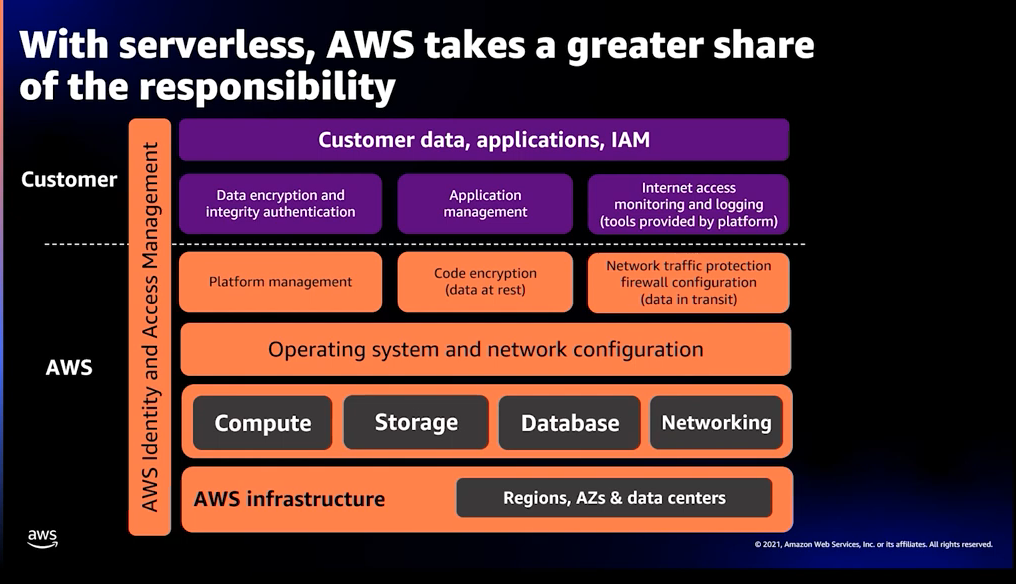
This is what cloud providers - in this case, AWS - calls “The Serverless Shared Responsibility Model”
 .
.
This diagram shows which parts are your cloud provider’s problem - like OS and network configuration - and which part you should worry about, like validating user’s authentication.
As a rule of thumb, you can think about it like this:
They are responsible for the security OF the infrastructure.
You are responsible for the security IN the infrastructure.
Broadly, four security pillars require your attention when you’re developing in serverless:
- Authentication and authorization
- Data Security and Integrity
- Monitoring & Logging
- Brute force attacks
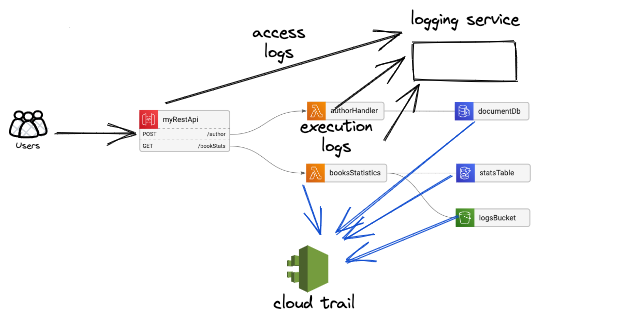
We’ll use this basic service architecture to explore these topics:
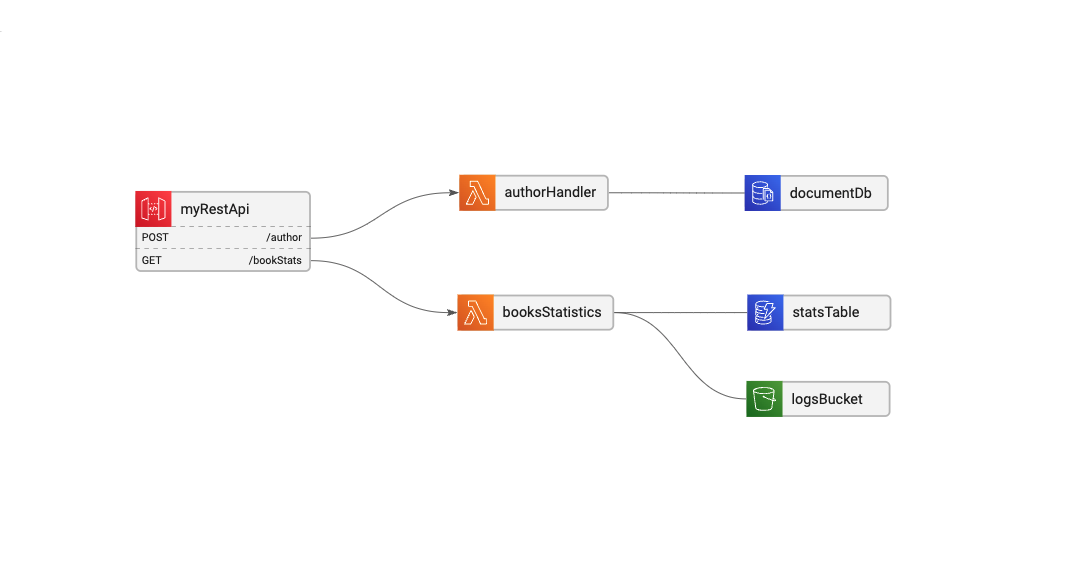
In this simple CRUD service we have 2 routes: POST: /author to create and update authors, and GET: /booksStats to return information about the authors’ books statistics.
Each route is connected to its Lambda function, and each lambda has its data sources: The authorHandler uses a DocumentDB, and the booksStatistics is using both an S3 bucket and a DynamoDB table.
Authentication and authorization
The first step in security is to make sure you lock your door, and that nobody can enter unless they are supposed to.
- Authentication is verifying that you are who you say you are.
- Authorization is verifying that you’re allowed to do what you’re trying to do.
You’re probably already using some kind of authentication (OAuth, Cognito, JWT tokens, etc.) to let your users login and perform actions in your system - but when you’re using serverless, the authorization and authentication is not limited just to your users, but also to your resources - like Lambda functions and managed services.
One of the most important principles in security is the principle of least privileges - which means giving a user/process only the essential privileges to perform its role.
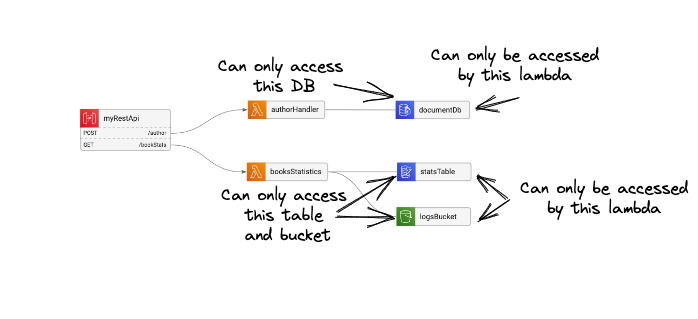
In the serverless case, this means that each resource - be it a Lambda, ECS Task, API gateway, or anything else - should only be able to access and trigger the specific resources it needs to complete its function.
For example, our authorHandler lambda in the diagram should only be triggered by the API Gateway, and should only have permissions to access the documentDB. The booksStatistics lambda should only be able to access our dynamoDB table and the S3 bucket.
This also means that if authorHandler is using a username/password combo to connect to our documentDB, then these secrets should not be visible to anyone who has access to the lambda (either via web console or CLI) - so they can not be, for example, stored as lambda Env Variable, but rather using services like AWS SSM.
Data Security and Integrity
So, once we’ve made our best effort to make sure all the locks are in place, we’ll want to make sure that even if someone does manage to break in, they won’t be able to steal anything important.
If you’re reading this, you probably know that you should never (ever!) keep plaintext passwords and that you should encrypt your data so if someone gets their hands on it, it’ll be useless. That’s a good start, but as you guessed, that is not enough.
Security-wise, data is a bit strange: It exists in 2 states - In transit and At rest.
In transit- When the data is being transported from one point to another (e.g: from your client to your server)At rest- When the data is stored for access, like an S3 bucket or a database.
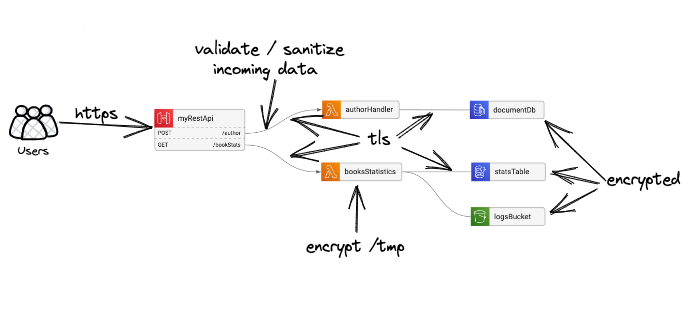
Your data should be encrypted in both of these stages - so all your connections should be encrypted (yes, like https if you’re using http), and all your data storage solutions - files, network drives, cache, database, buckets, etc.
In our example above, you’d probably want to encrypt the S3 bucket, the DynamoDB table (encrypted by default), and the DocumentDB - which is all correct - but there’s another vulnerability hidden here.
Although it’s often neglected, your Lambda’s /tmp folder is also a type of data store. Technically, if your Lambda is invoked frequently in a short time, the different invocations might have the same /tmp folder - which might lead to data leakage between invocations.
But it’s not enough to protect your data when it’s in transit and at rest` - you also need to make sure that no one is trying to lie to you - so basically, you need to do some data sanitation.
For example, a malicious user can enter John Doe; DROP TABLE users; when prompted to enter their name - and even though the string will be encrypted on the way to the server, and (maybe) stored securely on your database - you still don’t want this information processed as is.
Monitoring & Logging
Monitoring and logging is the cloud equivalent of putting security cameras in your business.
You want to be able to know who did what, for two reasons: First, if something goes wrong, you want to be able to find out what happened and how to fix it asap. Second, if someone might have gained illegal access to your system, you want to be able to know what they had access to.
There are numerous services for logging (DataDog, Logz.io, AWS CloudWatch, etc), and usually, each cloud provider has its own service that logs all the actions within the system - like AWS CloudTrail, GCP Cloud Audit, and Azure Sentinel
Brute force attacks
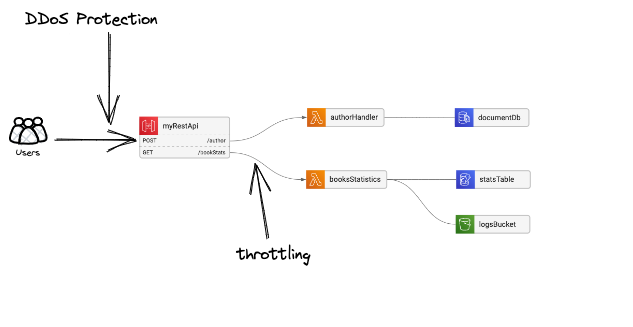
So you’ve made sure your doors and windows are locked, all the valuable data is encrypted and can not be used, and you have your security cameras installed to supervise everything in case something happens. But you still have the problem of spammers - unsolicited frequent visits that block your customers’ access. In the cloud world, that’s the equivalent of DDoS attacks on your network boundaries ( = everything exposed to the outside world). Most cloud providers offer basic DDoS protection, but you can help your system robustness using different tools like managing throttling rates/limit.
How to make sure everything (and everyone) keep everything secure?
All the topics above are both hard to handle and easy to neglect. While IaC (Infrastructure as Code) and serverless make a lot of things much easier, making sure that ease of development is not coming on the expanse of security is hard. In the next few post of this series we’ll explore which tools you can use to validate, monitor and build your infrastructure in a “security by design” approach.